-
 Atakante
11As a follow up to a question I asked Dave during last week's meeting, can we get a general sense about what data the AI models are trained on? Is it a fair assumption that they were fed all of the 3000+ factors from HSH during training? Similarly, were they then evaluated against out-of-sample test data?
Atakante
11As a follow up to a question I asked Dave during last week's meeting, can we get a general sense about what data the AI models are trained on? Is it a fair assumption that they were fed all of the 3000+ factors from HSH during training? Similarly, were they then evaluated against out-of-sample test data?
I ask b/c it feels right to look deeper into how AI predictions fare in real life with an eye towards their performance based on factors/variables the models were NOT trained on. Given tens of thousands of pace lines the models are using to make inference, it seems to me an uphill battle trying to prove them right/wrong with even couple hundred manually tracked races for those variables they already considered during training.
If memory serves, the chaos race variable/factor was NOT an input to the models so that's one candidate factor worthwhile manually diving into. Is it a safe assumption that race-level factors were excluded from training data? If not, is there a short list of other candidates or a shorthand logic to find others to manually "study"?
Thanks for any insights! -
 Dave Schwartz
455
Dave Schwartz
455
Very deep questions.
Not simple enough to answer in writing.
We'll have to discuss this in a meeting.
(Also, some will likely be proprietary.) -
Dave Schwartz
455As a follow up to a question I asked Dave during last week's meeting, can we get a general sense about what data the AI models are trained on? Is it a fair assumption that they were fed all of the 3000+ factors from HSH during training? Similarly, were they then evaluated against out-of-sample test data? — Atakante
A GENERAL answer would be: It started with one year of everything, plus multiple years for some of the small sample types.
As for what factors were permitted, the answer is all but a handful that had some known issues.
I do not understand what "evaluated against out-of-sample test data" means. If you mean was the AI TESTED, the answer is no.
I ask b/c it feels right to look deeper into how AI predictions fare in real life with an eye towards their performance based on factors/variables the models were NOT trained on. Given tens of thousands of pace lines the models are using to make inference, it seems to me an uphill battle trying to prove them right/wrong with even couple hundred manually tracked races for those variables they already considered during training. — Atakante
You are correct.
There is zero proof.
If memory serves, the chaos race variable/factor was NOT an input to the models so that's one candidate factor worthwhile manually diving into. Is it a safe assumption that race-level factors were excluded from training data? If not, is there a short list of other candidates or a shorthand logic to find others to manually "study"? — Atakante
Chaos = correct, but there was a fitness function involved.
Race Level: Nothing was left out.
___________________
The questions you have asked are actually pushing the envelope of need-to-know.
The AI is a very strong engine.
After my recent small sample test that was a day chosen at random, I am actually surprised that it performed so well.
I simply threw together a logical "system" based upon what has been discussed and it crushed the game. After going back and correcting a handful of races I had tagged, and correcting a few mistakes, manually assembled these statistics.
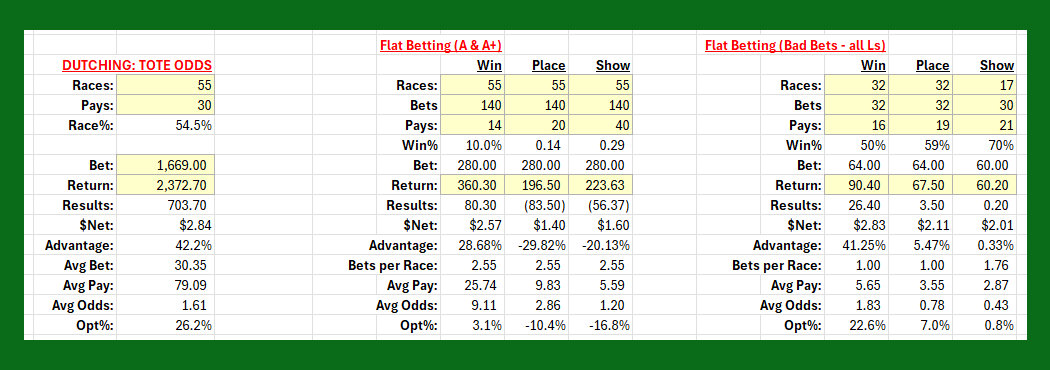
This is pretty amazing output.
DUTCHING: TOTE ODDS represents the actual dutched betting for the 55 races.
FLAT BETTING (A, A+) represents betting $2 on each A or A+ horse. IOW, betting only the horses that computed as having a $2.20 or higher $Net.
FLAT BETTING (BAD BETS) represents all the horses bet that were not A or A+ HORSES (according to the rules provided). -
 Tom Atwater
20That is very impressive, thanks Dave.
Tom Atwater
20That is very impressive, thanks Dave.
Question: The A/A+ grades were based on the final tote odds line, correct? -
Atakante
11Thanks, Dave for the detailed explanation. I naturally have an inquisitive mind so trying to get a better read of the system at hand so I don't make wrong assumptions. Of course, it is for you to judge what parts you consider trade secret...no issues there.
Also, I am not in any way trying to deny the early betting results you shared with us last week. It does support the evidence of valuable signals in picking winners and identifying profitable bets.
About out-of-sample testing, usually when folks build machine learning models they also set some subset of the data aside, e.g., randomly sampled 10%. Then, the model is trained using any appropriate algorithm for the task at hand. After training, the out-of-sample test data is fed to the model to judge how it performs against it before it is used in real life. The whole idea is to avoid overfitting as most ML models are prone to it, some more than others.
Another way to do it is setting aside a certain time slice instead of a randomly selected % of the observations/rows. For instance, I may be working with historical data from 2017 to 2023 for a given problem and I use the data from 2017 to 2022 to train my model and then validate it against the 2023 data. Because it has not been exposed to the 2023 data during training, it gives me a sense of the real-life performance of the model. Some algos are very good at memorizing training datasets, which can result in superb in-sample accuracy against training datasets that cannot be replicated against new data. Hope this explains... -
Dave Schwartz
455
The challenge with the approach you have outlined has many challenges.
_____________________
1. Since all the handicapping is dynamic, there is no mechanism that would allow automated testing.
Thus, to test against (say) 5,000 races, SOMEONE would have to literally bang those 5,000 races in manually.
In addition, if you DID pound in (say) 5,000 races, you'd logically want to do it live. Those 55 races took me about 6 hours with the tracking. That would put a 5k test at around 550 hours.
_____________________
2. Because I cannot have the data being exported and, therefore, easily available to the whale world, there can never be an automated testing process.
_____________________
3. Because the whales are the great influencer of our time, and they retrain their models annually, this new testing will need to be done once a year.
_____________________
FWIW...
In my 3+ decades in the horse betting business, I have found that the typical handicapper has no problem using the concepts and factors that he THINKS are important, and will use those without hesitation, despite the fact that he has done no real vetting.
He will consider a single pretty good day as enough proof to start using his new idea.
I suggest that the only way forward with The deTERMINATOR is to adopt a similar belief system.
Remember, I never said that AI BEST HORSE is the answer that will make you a professional. You will probably need to add your own secret sauce to make it work the way you want it to. (Truth be told: I already have created my own, derived BEFORE I did the 55 races.)
I really don't want 200 guys doing the same thing.
In fact, I'd make that a requirement if I could.
(On that particular topic, I have a practical answer.) -
Dave Schwartz
455Since there is no database there cannot be any testing unless it is done manually.



Please register to see more
Forum Members always see the latest updates and news first. Sign up today.